Overview of Statistical Techniques
Below, I give an overview of new statistical methods that are introduced in Science: Under Submission and provide links to the relevant Matlab code. I do not reflect on the foundations of science and statistics here, but just summarize the techniques that are proposed in the book.
To introduce some notation, say a detective wants to estimate a person's height (in cm) on the basis of her (or his) length of the right foot (in cm). The following formula could be used to estimate the height of a person,
The bigger the right foot is, the taller a person is estimated to be. For a data set of N observations, the estimated height of person n = 1, 2, ..., N is referred to as ŷn. The values 17 and 6 are called parameters and are denoted as b0 and b1 respectively. These parameter values have been optimized on the basis of a data set. In a model such as this, the length of the right foot of a person is known as the regressor xn,1. If we allow for multiple regressors xn,k with k = 1, 2, ..., K to predict a person's height, the linear regression model is given by
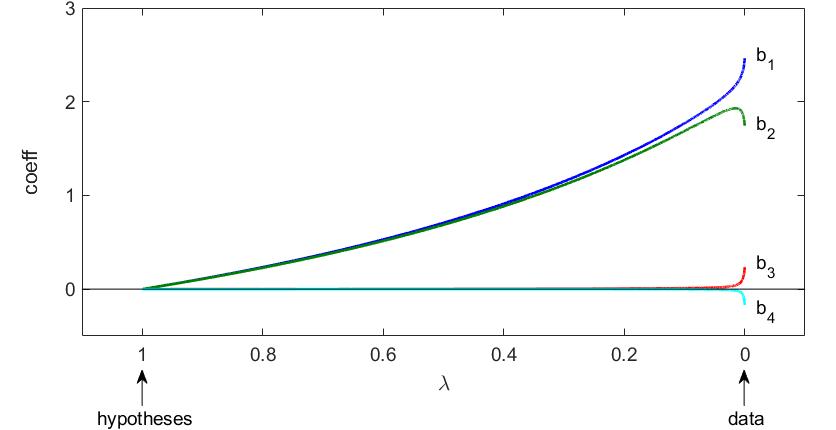
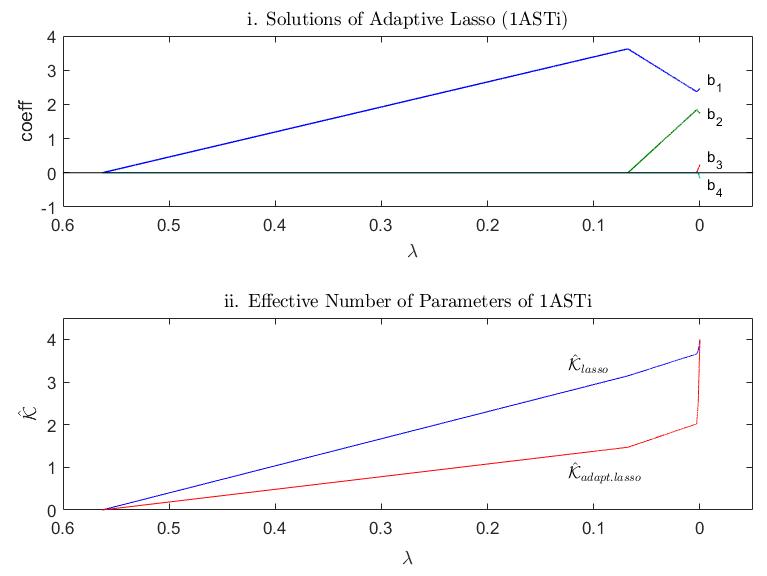
A researcher might have hypothesized that the length of a person increases by 4 rather than 6 times the length of the right foot. Current statistical techniques hardly enable a researcher to anticipate and influence how the in-sample accuracy of the data-optimized solutions is balanced with the simplicity of sticking to the hypotheses. I offer an intuitive approach to control such an accuracy-simplicity tradeoff (AST).